軟件發展主要是兩件事:簡單性和模塊化,簡單是簡化情況以解決問題,模塊則是為了分工合作。大數據發展完美詮釋了這個過程。
大數據,是在網頁檢索中發展起來的,其中關鍵是 Google,它奠定了大數據技術的基礎。
網頁檢索,海量數據,面臨很多挑戰。
海量網頁存(cun)儲,但現有存(cun)儲系(xi)統,“貴”、“不(bu)易擴展”、“數據存(cun)儲還不(bu)可靠”(注:Raid5重(zhong)建,慢,且重(zhong)建過(guo)程中壞盤,則就(jiu)無法(fa)恢(hui)復了)。
Google據(ju)此,推出GFS分布(bu)式文件系統,它有如下特點:

■ 獨立元數據節點。
■ 不要Raid,多機存多份(使用廉價服務器群,并認為故障是常態)。
■ 不(bu)刪除(chu),不(bu)修改,只(zhi)添加和覆蓋(一(yi)次寫,多次讀)。
海量網頁需(xu)要建立索(suo)引,但現有數據庫寫(xie)入性能低,檢索(suo)起來慢。
分析,大數(shu)據(ju)下的讀(du)寫模(mo)型(xing)(xing)和(he)傳統數(shu)據(ju)庫有(you)差異(yi),傳統數(shu)據(ju)庫模(mo)型(xing)(xing),大量(liang)時間在(zai)硬盤尋址上(shang),所(suo)以Google推出BigTable非關系型(xing)(xing)數(shu)據(ju)庫,它有(you)如下特點:
■不要多表 。
■不要回滾 。
■不要格式校驗 。
■不要觸發器 。
■批量讀數據,減少磁頭尋址時間。
■數據容忍丟失,大量緩存,排好序一次寫。
■多費些硬盤,對關鍵值(zhi)Hash,快速查找 。
網(wang)頁詞頻分析,需(xu)分布式計算(suan),但編程復雜。
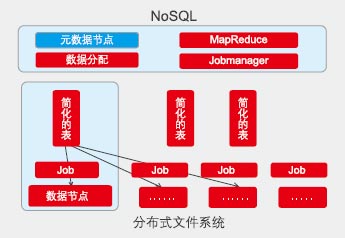
分(fen)(fen)析,計算(suan)(suan)(suan)過(guo)(guo)程中(zhong),大部分(fen)(fen)運算(suan)(suan)(suan)是矩(ju)(ju)陣(zhen)運算(suan)(suan)(suan),矩(ju)(ju)陣(zhen)運算(suan)(suan)(suan)可(ke)分(fen)(fen)解為(wei)小矩(ju)(ju)陣(zhen)乘(cheng)積。據此,Google推出(chu)MapReduce計算(suan)(suan)(suan)框架,它(ta)簡化計算(suan)(suan)(suan)模型,只(zhi)解決(jue)80%的場景問題,過(guo)(guo)程抽(chou)象如(ru)下:
■ Map過程:“數據分N份,每個數據獨立映射”,這部分可高度并發。
■ Reduce過程:數據集數據進行合并運算。
■ 分布式調度框(kuang)架:調度原(yuan)則為(wei)“移(yi)動計算比移(yi)動數據(ju)更便宜”。

檢索中(zhong),用(yong)戶輸入和(he)結(jie)果之間,是先(xian)知經驗,有各(ge)種(zhong)方法可定義經驗,Google的方法是“知識圖(tu)譜(pu)”,觀點(dian)是“數據(ju)足夠,通(tong)過(guo)常用(yong)的統計,足可模擬出大部(bu)分(fen)人(ren)的先(xian)知經驗”。
檢索中,多媒體(ti)理解的(de)(de)需求越來越多,Google提出的(de)(de)理念是:“數據比算法重要,如訓(xun)練數據合理且(qie)充分,簡單的(de)(de)模型也可無限逼近(jin)現實”,近(jin)年來,語音和智能識別的(de)(de)突破方向,也說明(ming)了這種趨勢。
大數據的(de)(de)發展歷(li)史(shi),給我們(men)很多(duo)啟示:“簡單(dan)拿來主義(yi)是不夠的(de)(de),更(geng)重要(yao)的(de)(de)是,要(yao)以問題出發,在行(xing)業(ye)理解的(de)(de)基礎(chu)上,模(mo)型充分簡單(dan)化,并(bing)在過程中,要(yao)有打破(po)傳統思維的(de)(de)勇氣”。



